728x90
728x90
게시글 제목: Speller100: Zero-shot spelling correction at scale for 100-plus language
게시글 원문: https://www.microsoft.com/en-us/research/blog/speller100-zero-shot-spelling-correction-at-scale-for-100-plus-languages/
💁♂️ 왜 읽으셨나요?
- 채팅 내 오류(Spell and Grammatical Error)를 교정하는 것은 번역 품질에 큰 영향을 끼친다.
- 마찬가지로 검색 연구에서도 질의문(Query)의 오류를 교정하는 게 검색 결과에 큰 영향을 끼친다.
- 질의문은 채팅처럼 (1)텍스트가 짧고, (2)교정에 많은 시간을 할애하기 어렵다는 특징을 공유한다.
- 즉, 질의문에서 활용된 오류 교정 연구를 참조하면 채팅 철자 오류 교정 연구에 도움 되는 정보도 얻을 수 있을 것.
- Bing (Microsoft)과 Google (Google), 네이버 (Naver)등의 검색 엔진은 질의문에 포함된 오류에 어떻게 대응하고 있을까?
📌 연구 키워드
- 저자 정보
- Jingwen Lu (Principal Applied Science Manager at Microsoft)
- 원래부터 검색 연구하시던 분으로 보인다
- 2022.12.10 LEAD: Liberal Feature-based Distillation for Dense Retrieval
- 2022.10.21 SimANS: Simple Ambiguous Negatives Sampling for Dense Text Retrieval
- 2022.09.27 PROD: Progressive Distillation for Dense Retrieval
- 2020.02.05 Aligning the Pretraining and Finetuning Objectives of Language Models
- Jingwen Lu (Principal Applied Science Manager at Microsoft)
- 자연어처리 (NLP, Natural Language Processing)
- 정보 검색 (IR, Information Retrieval)
- Self-supervised Learning
- Few-shot Learning
- Zero-shot Learning
- 철자/문법 오타 교정 (SC/GEC, Spell and Grammatical Error Correction)
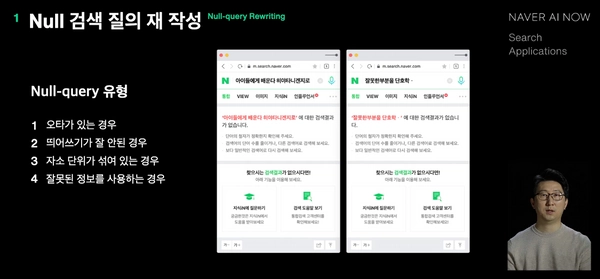
- Null 검색 질의(Null-query)
🕵️ 내용 정리
- 연구 배경
- Microsoft은 Bing에 입력된 전체 사용자 검색 중, 15%의 질의에 잘못된 철자가 포함됐었다고 말한다.
- 여담이지만, 다른 검색 회사 연구를 보면 10%라고 말하는 곳도 있다.
- 철자 오류를 포함한 질의는 검색 엔진이 최적의 검색 결과를 찾기 어렵게 만든다.
- Bing 검색의 첫 번째 단계는 오타를 교정하는 것이고, Micrsoft는 철자 교정에 거대 언어 모델을 활용
- 초기에는 24개 언어에 대해서만 고품질 교정을 지원했고, 현재는 100개 이상 언어로 확장된 상태
- 그러나 언어 모델 학습을 위한 학습 데이터 구축 과정에서 몇 가지 현실적인 어려움을 확인
- 영어와 독일어는 언어 리소스도 많고 피드백도 많아 데이터 구축이 쉽다.
- 룩셈부르크어와 아프리카어는 리소스가 적고, 피드백도 적어 데이터 구축이 어렵다.
(*이때 사용자 피드백이 무엇인지는 아래에서 설명을 적었습니다.)
- Microsoft은 Bing에 입력된 전체 사용자 검색 중, 15%의 질의에 잘못된 철자가 포함됐었다고 말한다.
- 제안 요약
- 모든 언어의 리소스가 충분치 않더라도 다국어 오류 교정이 가능한 Speller100 모델 개발
- 본 모델은 (1) 사전 학습된 언어 모델(PLM, Pretrained Lagnuage Model)과 (2) Few-shot Learning을 결합한 모델
- 정확하게는 저자들이 사전 학습을 시킨다.
- 글 제목은 Zero-shot인데, 왜 Few-shot Learning을 하느냐, 이것에 관한 답은 아래에서 확인하자.
- Microsoft는 오타 교정 문제를 Seq2Seq문제로 바라보았다.
- 오타 교정은 크게 Detection and Correction과 Seq2Seq 방법론으로 나뉘는 듯하다.
- 오타를 텍스트의 노이즈(Noise)로 본다면, 오타 교정은 손상된 텍스트를 복원(Denoise)하는 연구로 볼 수 있다.
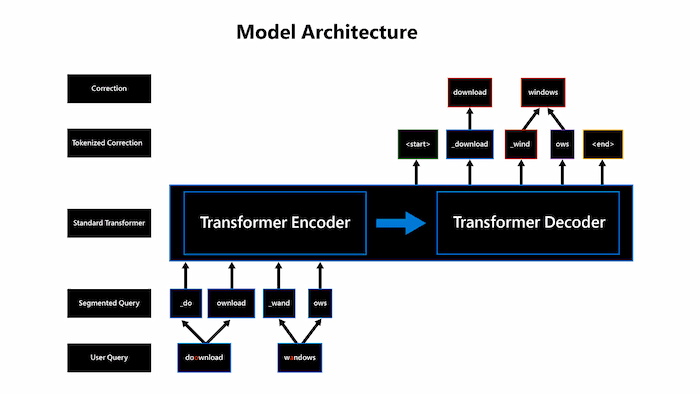
- 트랜스포머(Transformers) 기반 Encoder-Decoder 모델 제안
- 제안 방법
- (Speller100이 제안된 2021년 당시) BERT, UniLM, DeBERTa 같은 거대 언어 모델이 놀라운 혁신을 일으켰다.
- 그러나 그 언어 모델들을 들여다보면, 철자 오류 교정과는 조금 결이 다르다는 걸 알 수 있다.
- 기존 PLM은 WordPiece, SentencePiece 단위로 토큰을 나눈 뒤, MLM (Masked Language Model) 학습으로 '구', '문장' 수준의 의미를 잘 이해하기 위해 학습했지, 철자를 이해하기 위해 학습된 거라 보기 어려움.
- Speller100은 두 가지 학습 단계(Pre-training - Fine-tuning)로 나뉜다.
- Pre-training 단계에서는 철자 단위의 이해를 증진하는 학습 방법을 모델링
- Facebook BART (2020)의 사전 학습 방법에서 영감을 받았다.
- BART는 자동으로 손상된 텍스트를 만들고, 복원하는 Self-supervised Learning을 활용
- 손상된 텍스트는 토큰 순서 바꾸기 및 삭제, 삽입으로 만들어 냈다. (*그림 1 참조)
- 글에선 자세히 설명 안 하지만, BART 학습을 철자 단위(Character-level)로 수행한 듯(*그림 2 참조)
- (아마 MLM도 학습했을 듯) 위 방법으로 사전 학습만으로도 리소스가 적은 언어에서 Recall 50% 달성
- 아마 이걸 두고 Zero-shot Learning이라 말한 게 아닐까 싶다
- 사전 학습만 했는데 어떻게 교정이 돼요라 묻는 분이 혹시 계신다면, 본 모델이 Encoder-Decoder 구존인 것을 기억하자.
- Fine-tuning 단계에서는 직접적으로 철자 오류 교정 데이터로 지도 학습(Supervised-learning)
- 사용자 피드백을 통해 다량의 오타 교정 데이터를 얻는 듯하다 (*그림 3 참조)
- 예를 들어 네이버는 검색어에 오타가 있을 때, 교정된 검색어를 제안 항목에 띄운다.
- 만약 그 제안을 클릭해서 재검색을 한다면, 이런 게 쌓여서 학습 데이터가 되는 것
- Microsoft 글에서는 자세히 설명 안 해주는데, 아마 이것 외에도 따로 데이터 구축도 하지 않을까?
- 문제는 룩셈부르크어나 아프리카어는 사용자가 적어서 이런 피드백이 잘 안 이뤄진다는 것
- 사용자 피드백을 통해 다량의 오타 교정 데이터를 얻는 듯하다 (*그림 3 참조)
- 🌟 각 나라의 언어는 서로 공유하는 부분이 있다는 언어학계 정설을 활용 🌟
- 이해를 돕기 위해 재미있는 영상을 하나 살펴보자 (https://www.youtube.com/shorts/Ewe3gqwXzfU)
- 한국과 일본은 이웃해서 그런지 비슷한 단어가 있다
- 물론 한국어와 일본어는 고립어라 알려져 있으므로, 본문에서 설명하는 것과는 경우가 다르다.
- 위 영상은 재미였지만, 언어학계에서는 많은 언어가 고립되지 않았다. 즉 서로 관련이 있다고 본다.
- 실제로 각 언어들끼리 비교할 때 비슷한 경우가 있다.
- 한국 표현 중에 이를 '어족(語族)'이라 말한다.
- 실제로 영어와 독일어는 같은 게르만어족에서 유래됐고, 단어를 살피면 비슷한 부분이 있다. (* 그림 4 참조)
- 즉 특정 언어에 대해서만 오타 교정 데이터로 학습했더라도, 같은 어족의 다른 언어에서도 성능 향상이 있다
- 물론 고립어가 아니라는 전제하에
- 위와 같은 방법으로 아프리카어 데이터는 부족했지만, 영어와 독일어 데이터를 학습하는 것만으로도 아프리카어의 오타 교정 성능이 향상되었다는 것
- 이런 점에서 Zero/Few-shot Leraning이라는 키워드도 언급된 듯하다.
- 이해를 돕기 위해 재미있는 영상을 하나 살펴보자 (https://www.youtube.com/shorts/Ewe3gqwXzfU)
- Pre-training 단계에서는 철자 단위의 이해를 증진하는 학습 방법을 모델링
- 결론
- 상기 방법을 통해 오타 교정의 Recall과 Precision 모두 두 자릿수 이상 성능 개선
- 이게 언어별 평균인지.. 는 안 가르쳐준다
- 상승폭도 추상적으로 '두 자릿수' 이렇게만 말해준다
- 본 모델의 오타 교정으로 100개 언어의 모든 검색에서 개선된 결과를 얻었다고 보고
- Bing 검색 엔진에 대해 A/B 테스트를 수행했고, 아래와 같은 긍정적 결과를 얻었다.
- 오타로 인해 검색 결과가 아예 없었던 케이스(Null-query)가 최대 30% 감소
- 시스템의 오타 교정 검색어 추천에도 사용자가 직접 오타를 고쳐서 재검색한 횟수 5% 감소
- 시스템이 오타 교정 검색어 추천 시, 사용자가 제안을 받아들인 횟수 한 자릿수에서 67%로 상승
- 현재는 Bing에서 추천해주지 않고 바로 보여주지만, 옛날에는 추천만 해줬나 보다
- 제안을 받아들인 횟수가 향상됐다는 건, 그만큼 교정 성능이 올랐다는 의미
- 검색 결과 첫 페이지에서 사용자가 검색 결과를 클릭한 횟수 70%로 증가
- 오타 교정만 잘해도 검색 품질이 좋아진다는 이야기고, Speller100이 그것을 이룩해 냈다는 이야기
- 상기 방법을 통해 오타 교정의 Recall과 Precision 모두 두 자릿수 이상 성능 개선



🤔 이 글을 통해 배울 수 있는 점
- 한국어에서는 오타의 종류를 정의할 때, 단순 철자 오류와 문맥 의존 철자 오류로 구분한다.
- 본 글에서는 이와 대응되는 의미의 용어가 무엇인지 알 수 있다
- Non-word Error: 오타로 인해 실세계에 없는 단어가 작성된 것 (e.g., 감자 → 감쟈)
- Real-word Error: 오타로 인해 실세계의 다른 단어로 작성된 것 (e.g., 사진 → 사전)
❓ 여전히 궁금한 부분
- 사실 검색을 잘 모르는 이야기이고, 또 같은 어족 언어끼리 서로 영향을 준다는 건 흥미로운 이야기다
- 그래서 궁금한 점은 많다. 데이터나.. 어떤 언어들이 연관성을 크고 작게 주고받았는지 등등
- 그런데 이런 건 검색 회사 입장에서 영업 비밀 같은 거라 안 알려주는 것도 이해는 한다.
- 애초에 이게 논문이 아니라 기술 보고서 같은 글이니까.
- 단지 chatGPT 때도 느꼈지만, 오타 교정에 거대 언어 모델 사용하는 게 쉽지 않은데... 어떻게 빠른 속도로 처리한 걸까?
- 이런 기술적(?)인 부분은 잘 몰라서 항상 신기방기하다
320x100
'자연어처리(NLP) > Spell and Grammatical Correction' 카테고리의 다른 글
| [리뷰] GECToR – Grammatical Error Correction: Tag, Not Rewrite (0) | 2023.05.01 |
|---|---|
| [리뷰] A Simple Recipe for Multilingual Grammatical Error Correction (0) | 2023.04.07 |


